pages
저번 디렉토리 구조를 살펴볼 때도 봤지만
next.js는 pages 디렉토리 아래에 둔 하위 디렉토리를 알아서 url 경로로 지정해준다.
article
article은 ArticlePreview 컴포넌트를 눌렀을 때 이동되는 Article의 상세 페이지다.
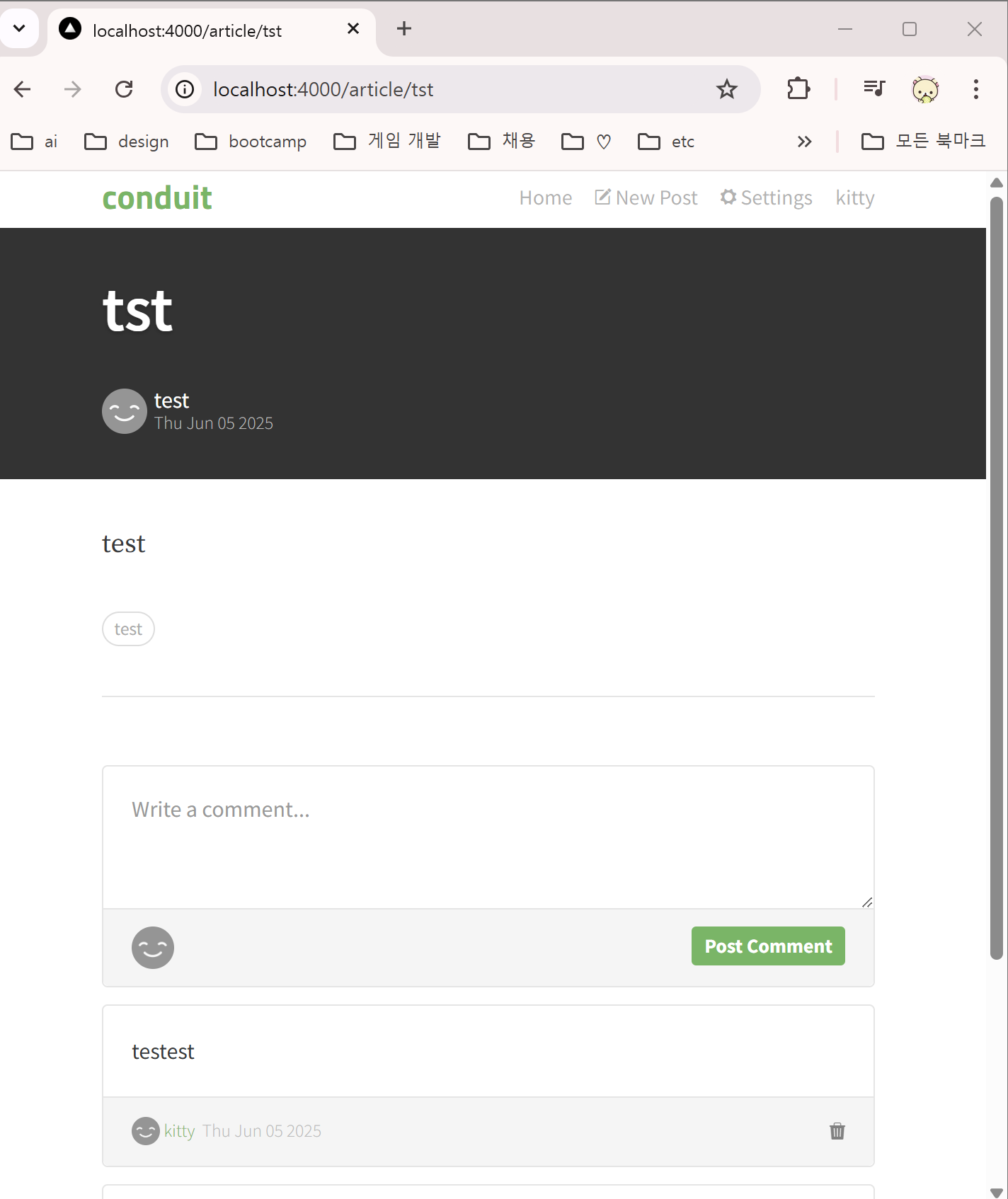 코드를 한 줄 한 줄 읽어보자. ### 읽어보기
코드를 한 줄 한 줄 읽어보자. ### 읽어보기 일단 ArticlePage라는 함수로 initialArticle이라는 Props를 받는다.
const ArticlePage = (initialArticle) => {초창부터 궁금한 점이 생겼다.
왜 { }로 감싸서 구조분해할당을 사용하지 않는거지?
하고 밑을 쭉 봤는데
굳이 initialArticle을 분해해서 사용할 필요가 없기 때문에
구조분해할당을 사용하지 않은 것 같다.
하지만 현재 프로젝트에서 타입스크립트를 사용하고 있으니
데이터 타입을 명확히 하고 어떤 props를 받는지 한눈에 알 수 있게 하기 위해
{ }로 감싸주는게 좋을 것 같다고 생각했다.
그러고 useRouter를 활용해 현재 페이지의 라우팅 정보에 접근한다.
pid로 받아오고 있으니 쿼리값도 pid로 받아온다.
const router = useRouter();
const {
query: { pid },
} = router;근데 내가 저번에 아티클 페이지의 엔드포인트를 slug 형태로 인코딩하는식으로 바꿨었다.
고로 pid 값도 slug로 바꾸는게 좋을 것 같아 comment와 함께 query 값을 고쳐줬다.
그 후 fetchedArticle에 useSWR로 데이터를 패칭해서 가져온 걸 저장한다.
useSWR은 캐싱과 재검증, 에러 처리 등을 자동으로 해준다.자세한건 추후 SWR과 tanstack을 비교할 때 공부해보는걸로..initialData로 서버사이드에서 가져온 데이터를 초기값으로 설정해준다.
const { data: fetchedArticle } = useSWR(
`${SERVER_BASE_URL}/articles/${encodeURIComponent(String(pid))}`,
fetcher,
{ initialData: initialArticle }
);그러고 article에 fetchedArticle이나 initalArticle 중에서 가능한 데이터를 선택해 추출한다.
const { article }: Article = fetchedArticle || initialArticle;근데 여기서 또 궁금했던 것..
현재는 전체 객체를 Article 타입으로 지정하고 있는데
실제로는 article 속성만 Article 타입이어야 한다.
그니까 지금은 fetchedArticle || initialArticle
이 전체를 Article 타입으로 설정하고 있다.
근데 fetchedArticle이나 initialArticle 둘 중에
실제로 갖고온 속성만 Article 타입으로 갖고와야하지 않는가.
그래서 따로 articleData에 먼저 비교하고 거기서 받아온걸 article에 넣었다.
const articleData = fetchedArticle || initialArticle;
const { article } = articleData;그 후엔 렌더링하고, getInitialProps로 초기데이터를 가져오는 부분이 적혀있다.
즉 article 페이지를 세 문장으로 설명하자면
- 서버에서 getInitialProps로 initialArticle을 생성하고
- 클라이언트에서 페이지가 렌더링되면
- useSWR이 fetchedArticle로 최신 데이터를 요청해서 가져와 렌더링한다.
분리하기
근데 지금 ArticlePage 한 함수 안에 라우팅도 있고, 데이터 페칭도 있고, 처리도 있고, 렌더링도 하고 책임이 너무 몰려있다는 생각이 들었다.
Hook을 분리해야 될까 라는 생각이 들었는데,
물론 구현 상세가 노출되어 맥락이 많지만
다른 컴포넌트에서 이 컴포넌트를 사용할 가능성이 있는가?
라고 물으면 아닌 것 같아서 따로 분리하지 않고 원래대로 냅뒀다
다만 렌더링은 너무 길게 읽힌다는 느낌이 있어 컴포넌트로 분리해서 추상화했다.
하지만 이렇게 하면 시선을 이동해서 다시 읽어야 한다는 단점이 있긴 한데..
나는 이게 더 읽기 좋은 것 같다고 느껴져서 이렇게 했다.
구현 상세가 그렇게까지 드러난 로직들은 아니지만,
컴포넌트로 분리해서 쓰는게 낫다고 생각해서 이렇게 한 거고..
사실 정답이 없는 문제라 어려운 것 같다.
맨 처음에는
ArticleBanner와 ArticleContent, TagList, CommentSection으로 하나하나 나눴었다.
근데 이러다 든 생각이 어차피 ArticleContent와 TagList는 하나의 집합으로 되어있는데
굳이 이걸 다 하나하나 나눌 필요가 있는가란 생각이 들었다.
책임을 너무 세분화한다는 생각이 들었기 때문이다.
그래서 ArticleBody로 한 번에 통합시켰다.
그러고 다시 쭉 읽어보는데 뭔가 마음에 안 들었다.
왜지 라고 생각해보는데 화살표함수를 사용해서 그런 것 같았다.
굳이 화살표 함수를 사용할 필요도 없을 뿐더러
나는 일반함수를 쓰는게 읽기가 더 좋아서 좋아하기 때문에 일반함수로 고쳐줬다.
최종 코드
editor
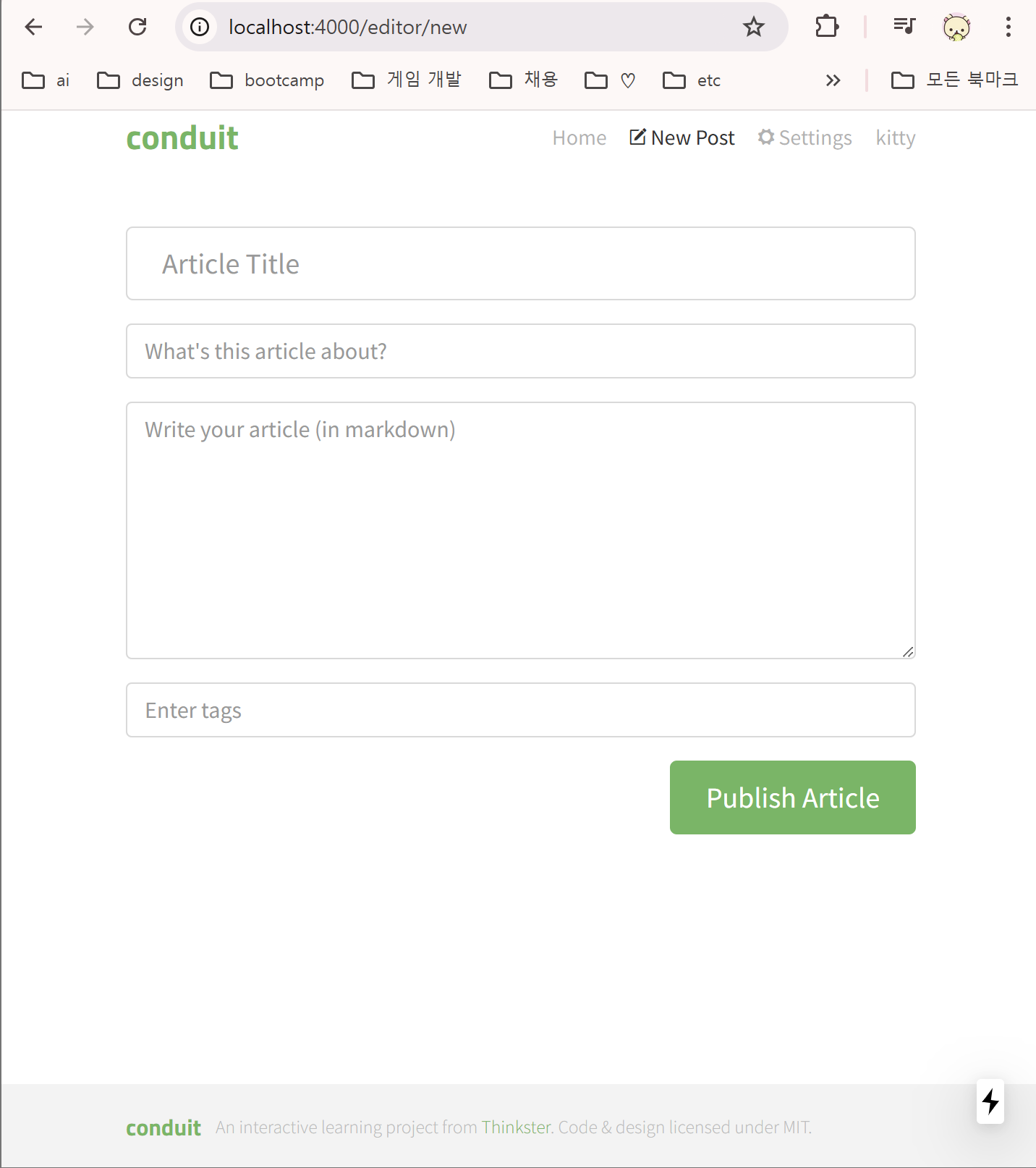
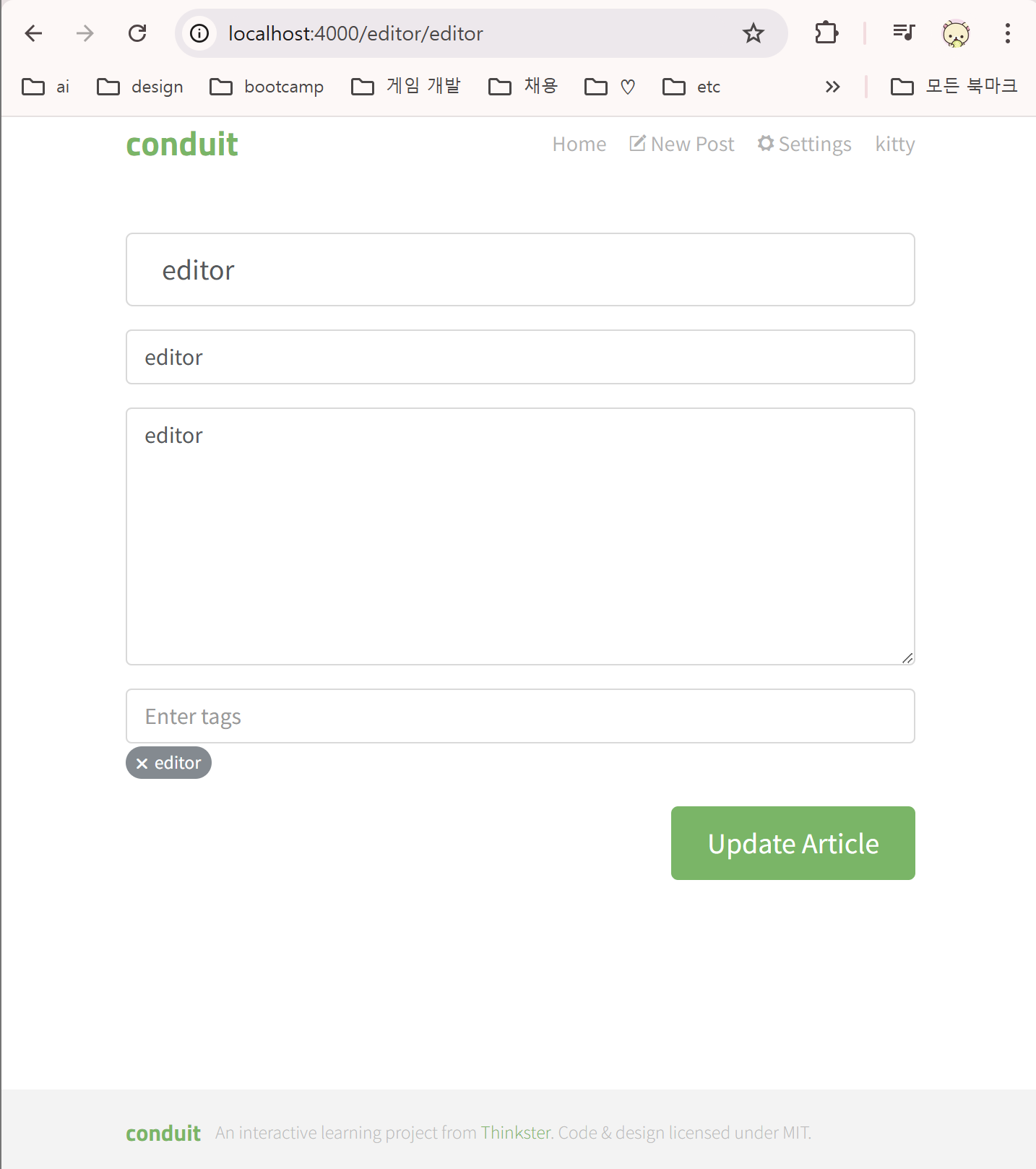
editor는
- 왼쪽 사진과 같이 새로운 글을 적을 때와
- 오른쪽 사진과 같이 원래 있던 글을 수정할 때
나타나는 페이지다.
 |  |
읽어보기
일단 두 페이지 코드 모두 전체적으로 주욱 봤을 때,
가장 먼저 눈에 띈 건 React를 사용하는 방식이었다.
기존에는 React 네임스페이스를 통해 직접 접근하는 방식을 사용하고 있었다.
import React from "react";
const [isLoading, setLoading] = React.useState(false);그래서 이를 named import 방식으로 변경했다.
import { useState } from "react";
const [isLoading, setLoading] = useState(false);이렇게 바꾸면 코드가 더 간결해지는 건 물론이고,
번들 크기 최적화에도 도움이 된다.
모던 번들러들이 이미 최적화를 잘 해주긴 하지만,
필요한 함수만 import하는 것이 의미적으로도 더 명확하다.
코드는 두 페이지에 비슷한 부분이 많기 때문에
번갈아가며 비교해보려한다.
먼저 새 게시글을 작성할 때는 모든 필드를 빈 값으로 초기화한다.
const PublishArticleEditor = () => {
const initialState = {
title: "",
description: "",
body: "",
tagList: [],
};
// ...
};반면 수정 페이지에서는
그 전에 작성했던 게시글의 정보를 갖고와야하기 때문에
article에서 데이터를 갖고와서(get) 초기값으로 설정한다.
const UpdateArticleEditor = ({ article: initialArticle }) => {
const initialState = {
title: initialArticle.title,
description: initialArticle.description,
body: initialArticle.body,
tagList: initialArticle.tagList,
};
// ...
};상태관리는 두 페이지 모두 동일한 패턴을 사용한다.
const [isLoading, setLoading] = useState(false);
const [errors, setErrors] = useState([]);
const [posting, dispatch] = useReducer(editorReducer, initialState);
const { data: currentUser } = useSWR("user", storage);여기서 흥미로운 점은 로딩과 에러 상태는 useState로,
게시글 관련 상태는 useReducer로 관리한다는 것이다.
왜 이렇게 분리했을까?
만약 게시글 상태를 useState로 관리했다면 이렇게 됐을 것이다:
const [title, setTitle] = useState("");
const [description, setDescription] = useState("");
const [body, setBody] = useState("");
const [tagList, setTagList] = useState([]);하지만 useReducer를 사용하면 관련된 상태들을 하나의 객체로 묶어서 관리할 수 있고,
상태 변경 로직을 컴포넌트 외부로 분리할 수 있어서
테스트하기도 쉽고 재사용성도 높아진다.
수정 페이지에서만 작성 페이지와 다르게
useRouter로 현재 페이지의 라우터 정보를 가져와서
url 파라미터를 관리한다.
const router = useRouter();
const {
query: { pid },
} = router;근데 이 페이지에서 엔드포인트가 slug 형태로 나타나기 때문에 pid를 slug로 바꿔줬다.pid도 parameter id라는 의미로 충분히 명확하지만,slug가 게시글의 제목이나 내용과 연관된 의미있는 URL을 만들어준다는 점에서
더 적절하다고 생각했기에 변경했다.
그리고 두 페이지 모두 title과 description, body, tag, submit의 상태를 관리한다.
각각의 핸들러 함수들이 어떻게 동작하는지 살펴보자.
먼저 title, description, body 핸들러를 보면 다음과 같다.
const handleTitle = (e) =>
dispatch({ type: "SET_TITLE", text: e.target.value });
const handleDescription = (e) =>
dispatch({ type: "SET_DESCRIPTION", text: e.target.value });
const handleBody = (e) => dispatch({ type: "SET_BODY", text: e.target.value });이 코드들은 dispatch를 통해 reducer에 action을 보내서 새로운 상태를 생성한다. dispatch란 어떤 작업이나 명령을 빠르게 보낸다는 의미를 가지고 있어서,
위 코드는 다음과 같은 과정을 거친다.
- dispatch(...) 호출
- editorReducer 호출
- 새로운 상태 반환
- posting 업데이트
이 과정을 통해 사용자가 입력한 값이 실시간으로 상태에 반영된다
하지만 위 코드에서 이벤트 객체 e에 타입을 지정해주지 않았기 때문에 경고가 발생한다.
그래서 각 입력 요소에 맞는 타입을 선언해서 사용했다.
type InputChange = ChangeEvent<HTMLInputElement>;
type TextareaChange = ChangeEvent<HTMLTextAreaElement>;
const handleTitle = (e: InputChange) =>
dispatch({ type: "SET_TITLE", text: e.target.value });
const handleDescription = (e: InputChange) =>
dispatch({ type: "SET_DESCRIPTION", text: e.target.value });
const handleBody = (e: TextareaChange) =>
dispatch({ type: "SET_BODY", text: e.target.value });태그 추가/삭제 함수들도 마찬가지로 타입이 없었기 때문에
string 타입을 명시해줬다.
const addTag = (tag: string) => dispatch({ type: "ADD_TAG", tag: tag });
const removeTag = (tag: string) => dispatch({ type: "REMOVE_TAG", tag: tag });다음으로 handleSubmit은 article을 제출 할 때 동작하는 함수다.
이 함수도 이벤트 객체에 타입 정의가 되어있지 않았는데,
폼을 전송할 때 발생하는 이벤트이므로 FormEvent 타입을 명시해줬다.
const handleSubmit = async (e: FormEvent) => {
e.preventDefault();
const errorMessage = validateArticle(posting);
if (errorMessage) {
alert(errorMessage);
return;
}
setLoading(true);
const { data, status } = await ArticleAPI.create(posting, currentUser?.token);
setLoading(false);
if (status !== 200) {
setErrors(data.errors);
}
Router.push("/");
};이 함수의 동작 과정은 다음과 같다
- e.preventDefault()로 폼의 기본 제출 동작을 막고
- validateArticle로 게시글 유효성을 검사한다
- 유효하지 않으면 경고창을 띄우고 함수를 종료한다
- 로딩 상태를 true로 설정하고
- API를 호출해서 게시글을 생성/수정한 후
- 로딩 상태를 false로 되돌린다
- 마지막으로 응답 상태에 따라
에러를 설정하거나 홈페이지로 리다이렉트 한다
new 페이지와 [slug] 페이지의 주요 차이점은 API 호출 부분에 있다.
새 게시글 작성 시에는 POST 요청을, 수정 시에는 PUT 요청을 사용한다.
수정 페이지에서는 기존에 axios를 직접 사용하고 있었는데,
article API에 update 로직이 이미 정의되어 있어서 이를 활용하도록 변경했다.
const { data, status } = await ArticleAPI.update(
{ ...posting, slug },
currentUser?.token
);여기서 { ...posting, slug }는 기존 게시글 데이터에 slug 정보를 추가해서 전달하는 것이다.
이렇게 하면 서버에서 어떤 게시글을 수정해야 하는지 알 수 있다.
분리하기
두 페이지는 공통되는 코드가 많다.
지금처럼 분리해서 사용하는게 좋을까,
아니면 하나로 통합해서 관리하는게 좋을까?
저번에도 비슷한 고민을 했지만
해당 페이지들에 공통적으로 들어가는 컴포넌트들은,
도메인이 동일하고 기능도 비슷한 면이 많기 때문에
수정이 필요할 때도 두 군데를 같이 수정해줘야 한다.
하지만 handleSubmit은 다르다.
공통되는 부분이 몇군데 있다고 하더라도,
원래 있는 아티클을 수정할 때는 put을 하고
새로운 아티클을 생성할 때는 post를 해야한다.
고로 handleSubmit은 지금처럼
별도로 관리하는 편이 낫다고 생각했다.
반면 렌더링 관련 컴포넌트들은
지난번에 만들었던 shared/ui 디렉토리에서 관리하고
EditorForm 컴포넌트를 만들어서 features에서 관리 후
pages에서 이를 불러오는 형태로,
공통적으로 관리하는게 좋다고 생각했다.
그래서 최종적으로 리팩토링한 코드는 아래와 같다.
- shared/ui/input/TextArea.tsx
- shared/ui/input/TextInput.tsx
- shared/ui/button/SubmitButton.tsx
- features/editor/EditorForm.tsx
최종 코드
profile
profile은
- 특정 사용자의 프로필 정보와
- 해당 사용자의 아티클,
- 해당 사용자가 좋아요를 누른 아티클
을 볼 수 있는 페이지다.
읽어보기
화살표 함수 일반 함수로 바꿔주고 쭉 읽는데
오잉
팔로우도 팔로잉이 트루고
언팔로우도 팔로잉이 트루여서 고쳐줬다
그리고 현재는 api 호출이 완료되기 전에 trigger가 실행 될 수 있어서
await를 추가해 api 호출이 완료 된 후에 trigger가 실행될 수 있도록 고쳤다.
mutate는 버튼을 클릭했을 때 화면을 먼저 업데이트해서 사용자에게 보여주는걸 의미한다.
mutate가 한국어로는 돌연변이(일상적으론 변화하다)라고 한다.
ui상태가 바뀌니까..~ 돌연변이 mutate. ㅋㅋ
그래서 수정한 코드는 아래와 같다.
async function handleFollow() {
mutate(
`${SERVER_BASE_URL}/profiles/${pid}`,
{ profile: { ...profile, following: true } },
false
);
await UserAPI.follow(pid);
trigger(`${SERVER_BASE_URL}/profiles/${pid}`);
}
async function handleUnfollow() {
mutate(
`${SERVER_BASE_URL}/profiles/${pid}`,
{ profile: { ...profile, following: false } },
false
);
await UserAPI.unfollow(pid);
trigger(`${SERVER_BASE_URL}/profiles/${pid}`);
}근데 이러고 또 가만 보는데..
데이터를 fetch할 땐 url을 인코딩해서 갖고오는데
const { data: fetchedProfile, error: profileError } = useSWR(
`${SERVER_BASE_URL}/profiles/${encodeURIComponent(String(pid))}`,
fetcher,
{ initialData: initialProfile }
);mutate에선 그냥 pid를 바로 사용하고 있는 형태로 url을 갖고오고 있었다.
음.. 둘 다 pid를 일관적으로 갖고오는게 낫지 않나? 라고 생각해서
url 전체를const profileUrl = ${SERVER_BASE_URL}/profiles/${encodeURIComponent(String(pid))}
와 같이 상수로 빼서 사용해줬다.
로직은 아티클이랑 비슷하게
- 서버에서 getInitialProps로 initialProfile을 생성하고
- 클라이언트에서 페이지가 렌더링되면
- useSWR이 fetchedProfile로 최신 데이터를 요청해서 가져와 렌더링한다.
분리하기
해당 페이지의 렌더링 컴포넌트도
너무 몰려있다는 느낌이 들어
아래 사진처럼 ProfileBanner와 ProfileContent로 컴포넌트를 분리해줬다.
라고 생각했는데 펀드멘탈 문서를 계속 읽어보다가
아... 너무 프롭스가 드릴처럼 두두두 뚫고 내려가는 것 같다는 생각이 들었다.
그래서 profile은 그대로 냅두는게 낫다고 생각했다.
그럼 아티클도 다시 조합 패턴을 하는게 맞나? 라고 한다면
아티클은 단순하게 역할에 맞게 딱, 딱 전달하고 있고
에디터는 하나의 큰 form을 공통으로 페이지이기 때문에
리팩토링 한 구조를 따르는게 괜찮을 것 같다고 생각했다.
최종 코드
user & root
읽어보기
user랑 루트 페이지는 읽는데.. 고칠게 없다는 생각이 들었다.
그래서 함수 선언 방식만 고쳐주고
handleLogout에 await가 없길래 추가 해줬다.
근데 신기했던게 next.js가 구버전이라 그런지,
이미지를 필요할 때만 불러오기 위해서
lazysizes 플러그인을 사용했던점이 신기했다.
if (typeof window !== "undefined") {
require("lazysizes/plugins/attrchange/ls.attrchange.js");
require("lazysizes/plugins/respimg/ls.respimg.js");
require("lazysizes");
}요샌 그냥 next/Image나
html 속성에 loading="lazy"로
딸깍 했는데 ㅋㅋ
찾아보니 옛날엔 lazy 속성을 제대로 지원하지 못하는 브라우저도 많아서
저렇게 플러그인으로 설정해주는 일이 많았나보담